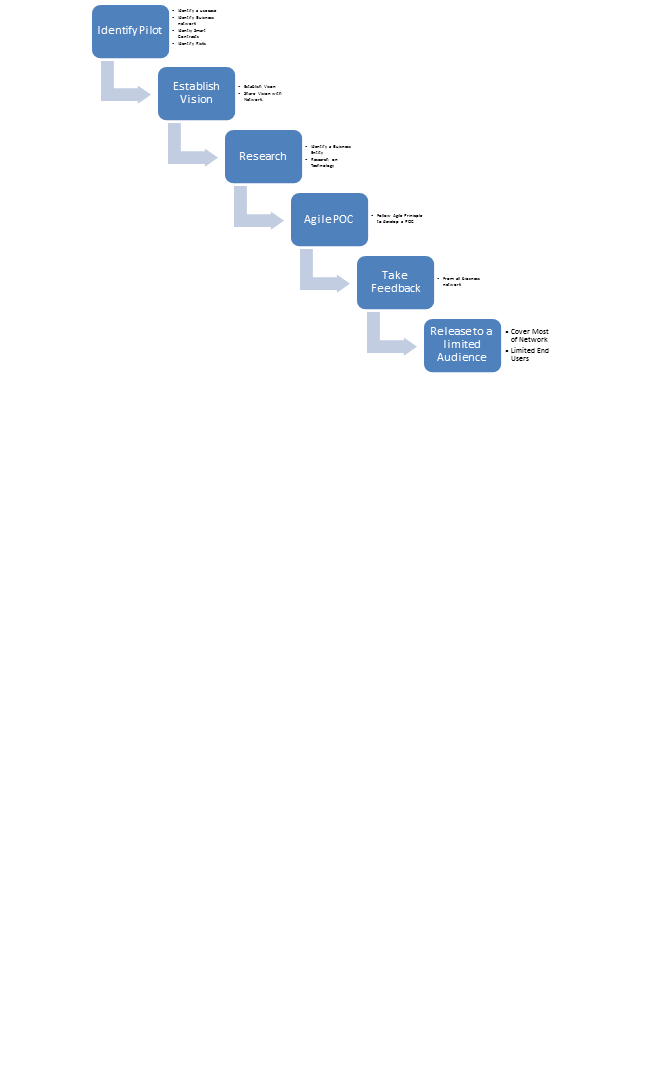
Blockchain in Insurance Claims
via Blockchain
Blockchain is a distributed ledger initially used by Bitcoin cryptocurrency and eventually by many banking organizations to record transactions between parties with high security. It is start of Blockchain arena and it is anticipated to have a long sustainability and acceptability in various industries.
One of the biggest use cases in Insurance Industry is adoption of blockchain in claim processing. Insurance contracts involve various parties as agents, brokers, repair shops and third party administrators involving manual work and duplication at various stages of value chain. Using blockchain, verification of transactions will be done without any human intervention and making it completely automated process at various stages.
Benefits for using blockchain in claim processing –
- The distributed ledger allows various parties to update the information securely like updating claim forms, evidence, police report etc helping in reduction of loss adjusted (LAE) expenses.
- Fraud Detection – As blockchain maintains a ledger of multiple parties, it has ability to eliminate any errors and frauds. Blockchain technology using the high computing power authenticates the customers, policies and transactions.
- Payments – Claim payments can be made without any need of intermediary authority for transaction validations which helps in reducing the overall operational cost of claims processing.
- As this is highly secured transactions, multi review process will be eliminated resulting into speedy claim processing.
Multithreading in real world
Most of you already know about threads and it’s benefits. This article will help you to understand how thread are being used in real world applications and what are the best practices. Threads are primarily used to achieve asynchronous behavior and multitasking.
Below are some common real life use cases where threads have been used effectively.
- Animation and Games.
- Most of the GUI tools like Swing uses thread to keep track of events generated from widgets.
- Internally Junit uses threads for executing test cases parallel.
- Most of the web servers uses multithreading to entertain HTTP Requests parallel
Below are some common best practices for developing concurrent (multi threaded )applications.
Naming a Thread-
Thread should be named for easier debugging. You can see in Eclipse that threads running in parallel with some random names like “Thread-124362563”. Giving a unique name to a thread will make it easier to identify the thread while debugging.
How many threads-
Before deciding number of threads to create , please keep in mind following facts.
- One processor executes a thread at a time and keeps switching between threads. Too much of switching can be an inefficient solution.
- Now a days most of the computers are multi core i.e comes with multiple processor so multiple threads can be executed simultaneously.
For long running threads one practice can be to have no of processors as no of threads.
Use Immutable Classes
Immutable classes, once created cannot be modified so one does not need to worry about sharing the state with multiple threads. This reduces a great scope of synchronization.
Threads VS JMS –
I have developers discussing JMS VS Threads for developing asynchronous behavior. I think JMS is more controllable way to use threads. JMS gives you additional features like tracking of request and retry to make a better enterprise choice.
Use Executors instead of Threads API
Object pool is a concept to avoid cost of object creation and destruction. JDK provides “Executors” as managed thread pool.
Use java.util.concurrent
Java 5 added a java.util.concurrent to the Java. This package contains a set of classes that makes it easier to develop concurrent scalable applications .Before this package was added , one need to use “synchronized” , “volatile” , “join” , “wait” and “notify” to write concurrent ( multi threaded applications) .
Popular items of “java.util.concurrent” are “BlockingQueue” , “semaphore” , “Lock Interface” , “CountDown Latch” and “CyclicBarrier”.
Giving some details about Locks , CountDown Latch and Cyclic Barrier.
Locks
Prior to java 5 “synchronized” and “volatile” were the means of achieving concurrency. “Synchronized” provides a clean way to code but comes with limitation like try lock i.e. acquire only if lock is available. For more scalable concurrent solution JDK added lock interface and various implementations. “Reentrant lock” is a popular implementation of Lock interface.
Synchronized acquired a intrinitc lock on object wihis realeased automaticaaly. Bot with Lock , one need to release a lock programiticaaly. Best practice is to relase the lock in try block.
Synchronized acquired a intrinitc lock on object wihis realeased automaticaaly. Bot with Lock , one need to release a lock programiticaaly. Best practice is to relase the lock in try block.
CyclicBarrier and CountDown Latch
Both CyclicBarrier and CountDown latch are used for thread synchronization i.e. thread waits for another thread to complete their job at some point. Difference between both is that Cyclic Barrier instance can be reused while CountDownLatch instance can not.
Logback is not writing specific log file Solution
Logback is not writing specific log file Solution Logback Configuration: <property name="DEV_HOME" value="/root/apps/logs" /> <appender name="FILE-AUDIT" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${DEV_HOME}/myapp.log</file> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- rollover daily --> <fileNamePattern>${DEV_HOME}/archived/myapp.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern> <timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <!-- or whenever the file size reaches the max --> <maxFileSize>${rolling.file.max.size}</maxFileSize> </timeBasedFileNamingAndTriggeringPolicy> <maxHistory>${rolling.file.max.history}</maxHistory> </rollingPolicy> <encoder> <pattern>${rolling.file.encoder.pattern}</pattern> </encoder> </appender>
Issue is related to conflict between log4j and Logback, when we migrate from old log4j to Logback. You need to exclude lo4j dependencies from existing dependencies by running this command:
$ mvn dependency:tree
= >Add these jars only for logging using SLF4j and Logback
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${version.slf4j}</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>${version.logback}</version> <scope>runtime</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> <version>${version.slf4j}</version> <scope>runtime</scope> </dependency>
Posted detail issue on StackOverflow:
Crawl and Index….. Nutch / elasticSearch – Partners in the making
Hi
In the internet era, there is an old tech saying – “Content is King” (inspired by old Jungle saying from Phantom.. 🙂 )
One of the common challenges in content management system is to extract the latest information. In the WWW world, it is commonly known as crawling. The king of the crawler world is Apache nutch.
elasticsearch (no more just the new kid in town) has already established itself as one of the top search platforms. It is only natural that companies are looking at using the both platforms together to achieve a better content management system specifically acquire, analyze, publish, search phase.
Here’s a quick and dirty guide to get them up and running quickly.
1. Download nutch
2. set NUTCH_HOME
NUTCH_HOME=/Users/madheshr/tools/apache-nutch-2.2.1
export NUTCH_HOME
3. Clean build
ant clean
ant
4. Verify new local deploy created under NUTCH_HOME/rutime
/Users/madheshr/tools/apache-nutch-2.2.1/runtime/local
5. Under bin sudirectory of local, create a new directory called urls
6. In urls create a new file called nutch.txt. Edit the file to add URLs to crawl
7. Enable crawler in conf/nutch-site.xml by adding the below lines within configuration tags
<name>http.agent.name</name>
<value>My Nutch Spider</value>
8. Note the value and enter the same in conf/nutch-default.xml as the
value for <name>http.agent.name</name>
9. Test by running the below command in local/bin
nutch crawl urls -dir /tmp -depth 2
Integrate Nutch and ES
1. Activate elasticsearch indexer plugin
Edit conf/nutch-site.xml
<property>
<name>plugin.includes</name>
<value>protocol-http|urlfilter-regex|parse-(html|tika)|index-(basic|anchor)|indexer-elastic|scoring-opic|urlnormalizer-(pass|regex|basic)</value>
<description>Regular expression naming plugin directory names to
include. Any plugin not matching this expression is excluded.
In any case you need at least include the nutch-extensionpoints plugin. By
default Nutch includes crawling just HTML and plain text via HTTP,
and basic indexing and search plugins. In order to use HTTPS please enable
protocol-httpclient, but be aware of possible intermittent problems with the
underlying commons-httpclient library.
</description>
2. Verify and add ES specific properties to nutch-site.xlm
<!– Elasticsearch properties –>
<property>
<name>elastic.host</name>
<value>localhost</value>
<description>The hostname to send documents to using TransportClient. Either host
and port must be defined or cluster.</description>
</property>
<property>
<name>elastic.port</name>
<value>9300</value>
<description>
</description>
</property>
<property>
<name>elastic.cluster</name>
<value>elasticsearch</value>
<description>The cluster name to discover. Either host and potr must be defined
or cluster.</description>
</property>
<property>
<name>elastic.index</name>
<value>nutch</value>
<description>Default index to send documents to.</description>
</property>
<property>
<name>elastic.max.bulk.docs</name>
<value>250</value>
<description>Maximum size of the bulk in number of documents.</description>
</property>
<property>
<name>elastic.max.bulk.size</name>
<value>2500500</value>
<description>Maximum size of the bulk in bytes.</description>
</property>
3. Create a new index in ES if it is not there already
<value>nutch</value>
curl -XPUT ‘http://localhost:9200/nutch/’
Java Code Quality
Hi
Most tech leads will readily admit that in large development projects, a major chunk of their effort goes towards ensuring good code quality. With the increase in number of developers, there is greater need for standardization the code which is enforced in the form of adherence to certain code quality. As a programming language, Java if fortunate enough to have several coding conventions defined by several companies including Oracle (Sun). However every company or even individual projects within a company often supplement the general standard with it’s own set of custom guidelines, rules and conventions.
Just like everything else in life, it is a simpler matter to define standards / guidelines. However it is an entirely different ball game to follow them. For architects and tech leads it is a question of ensuring the adherence. So, we are constantly on the lookout for efficient ways to accomplish this. One of our favourite tools is the Sonar – Java static code analysis tool from Sonarqube.
Here are some quick steps on how to get up and running with Sonar on a Mac system. Hope you find it useful.
Set up Sonar
Here’s a great link that i found
http://docs.codehaus.org/display/SONAR/Installing
1. Download sonar into some directory
For eg /Users/madheshr/tools/sonar-3.7
2. Create the sonar schema on MySQL
3. Edit sonar.properties in the conf directory and make below changes
– Specify DB parameters
– Webhosting mechanism: default is 127.0.0.1:9000
4. Create a startup script to start sonar
/Users/madheshr/tools/sonar-3.7/bin/macosx-universal-64/sonar.sh start &
Analyzing a project using sonar-runner
1. Download sonar-runner and extract it
/Users/madheshr/tools/sonar-runner-2.3
2. Edit conf/sonar-runner.properties to mention webserver name and DB name
Note: The default script has mismatched sonar schema names.
3. In the project home create a file sonar-project.properties. Note it is case-sensitive
Also confirm the path from which java code starts. May not be the main src itself
# required metadata
sonar.projectKey=my:iReconAdmin
sonar.projectName=iReconAdmin
sonar.projectVersion=1.0
# optional description
sonar.projectDescription=Admin utility for iRecon
# path to source directories (required)
sonar.sources=src
# The value of the property must be the key of the language.
sonar.language=java
# Encoding of the source code
sonar.sourceEncoding=UTF-8
4. Run using command sonar-runner
/Users/madheshr/tools/sonar-runner-2.3/
As always, all the mistakes are mine and all the credits go to the open source community.
Cheers..
Apache Common Pool – Object pool example
Advantage of using object pool is to improve performance of the application by saving time to create new object from other source for the same purpose. Object pool creates once and reuse for other subsequent operations on the same object. You can customize other configuration settings. Please visit this URL for more info: http://commons.apache.org/proper/commons-pool/api-1.6/index.html
Step:1 Add this Maven jar dependency in your POM.xml
<dependency> <groupId>commons-pool</groupId> <artifactId>commons-pool</artifactId> <version>1.6</version> </dependency>
Step:2 Create Factory Class
import java.io.InputStream;
import java.util.Properties;
import org.apache.commons.pool.BasePoolableObjectFactory;
import org.springframework.stereotype.Component;
/**
* @author Rajiv Srivastava
* Object pool factory
*/
//Extend BasePoolableObjectFactory class.
@Component
public class ObjectPoolFactory extends BasePoolableObjectFactory<ConnClient> {
// for makeObject we'll simply return a new object e.g: connection object
@Override
public ConnClient makeObject() throws Exception {
InputStream stream = null;
// Create object code here for the first time. e.g: Create connection object from other integrated system component
ConnClient connClient= new connClient();
return connClient;
}
}
Step:3 Create Object Pool class and usage
import org.apache.commons.pool.ObjectPool;
import org.apache.commons.pool.PoolableObjectFactory;
import org.apache.commons.pool.impl.GenericObjectPool;
import org.springframework.stereotype.Component;
/**
* @author Rajiv Srivastava
*/
@Component
public class ObjectPoolConnection {
private ObjectPool<ConnClient> pool;
ConnClient obj = null;
public ConnClient getConnClient(){
PoolableObjectFactory<ConnClient> factory = new ObjectPoolFactory();
pool = new GenericObjectPool<ConnClient>(factory);
try {
try {
if(obj==null){
obj = (ConnClient)pool.borrowObject();
}
} catch (Exception e) {
obj=null;
logger.error("failed to borrow object from Connection pool"+e.getMessage());
} finally {
if (obj != null) {
try {
pool.returnObject(obj);
} catch (Exception e) {
logger.error("failed to return object from Connection"+e.getMessage());
}
}
}
} finally {
try {
pool.close();
} catch (Exception e) {
logger.error("failed to return pool"+e.getMessage());
}
}
return obj;
}
}
2014 in review
The WordPress.com stats helper monkeys prepared a 2014 annual report for this blog.

Here’s an excerpt:
A New York City subway train holds 1,200 people. This blog was viewed about 6,100 times in 2014. If it were a NYC subway train, it would take about 5 trips to carry that many people.
Cassandra DataStax – Developer Guide with Spring Data Cassandra
We will discus Cassandra implementation :
Important Points:
- http://www.datastax.com/documentation/cassandra/2.0/cassandra/gettingStartedCassandraIntro.html
- Recommended stable production version – DataStax Enterprise 4.5. (When this article as written)
- Compound Partition and Clustered keys- http://www.datastax.com/documentation/cql/3.0/cql/ddl/ddl_compound_keys_c.html
- Spring-Data-Cassandra API and reference docs- http://projects.spring.io/spring-data-cassandra/ (Current release- 1.1.0.RELEASE)
Download and Installation:
1. Tarball Installation
- DataStax DB
- You need to register yourself with DataStax for download.
- DataStax Enterprise – http://www.datastax.com/download#dl-enterprise.
- Create These folders and changed permission:
- sudo chmod 777 /var/log/cassandra
sudo mkdir -p /var/lib/cassandra/data
sudo chmod 777 /var/lib/cassandra/data
sudo mkdir -p /var/lib/cassandra/commitlog
sudo chmod 777 /var/lib/cassandra/commitlog
sudo mkdir -p /var/lib/cassandra/saved_caches
sudo chmod 777 /var/lib/cassandra/saved_caches - How to run Cassandra: Go to DataStax Cassndra installed folder on Mac/Linux/Unix env:
cd /Users/<userName>/dse-4.5.2/bin</pre> <pre>sudo ./dse cassandra -f //This above command Cassandra DB on your local system. Hit enter to quit from ruining server in background and start CQL query console. sudo ./cqlsh
- Create Schema:
CREATE SCHEMA event_owner WITH replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’ : 1 };1. Schema(Keyspace) name: event_owner
2. Table name: event_audit
Table creation syntax:Please find the revised data model and details below.Note: I have used expanded names for easier understanding which can be shortened later on.
CREATE TABLE event_owner.event_audit (
ctg text,
month timestamp,
ctgid text,
ver timeuuid,
userid text,
action text,
content text,
PRIMARY KEY ((category,month),cat_id,version)
) WITH CLUSTERING ORDER BY (cat_id ASC, version DESC);
Sample Data - category | month | cat_id | version | action | content | userid
———-+————————–+——–+————————————–+——–+————–+———–
CC | 2014-01-01 05:30:00+0530 | 8000 | b3fc48e0-5608-11e4-aacd-e700f669bcfc | DRAFT | json content | 155045940
CC | 2014-01-01 05:30:00+0530 | 9000 | a4747460-5608-11e4-aacd-e700f669bcfc | DRAFT | json content | 155045940Description- category
- Commitcode / Part Association/ EventTag [CC / PA / ET]
- month
- 12 AM timestamp of first day of the month the change is made
- cat_id
- Unique id for a particular category [Say inc axe of commit code it is cc_id say 9000]
- version
- it is the unique id that indicates the version number.
- You can populate it using now() function.
- It has an embedded timestamp that can be used to know the timestamp. Use dateOf() function to get the timestamp value.
- userid
- id of the user who made the change
- action
- SAVEDRAFT/ PUBLISH / DELETE etc.
- content
- actual json content after the change [full json]
- category
Sample Query to access the data
cqlsh:cdb> select * from audit where category=’CC’ and month=’2014-01-01 05:30:00+0530′ and cat_id=’9000′;
category | month | cat_id | version | action | content | userid
———-+————————–+——–+————————————–+——–+————–+———–
CC | 2014-01-01 05:30:00+0530 | 9000 | a4747460-5608-11e4-aacd-e700f669bcfc | DRAFT | json content | 155045940- SQL Like Commands: You can use same standard SQL DDL/DML commands/syntax for Cassandra query, like-
- Drop table
- Update
- Delete
- Truncate
- Select query
2. DataStax OpsCenter-
http://www.datastax.com/what-we-offer/products-services/datastax-opscenter
3. DataStax DevCenter
Installation: DataStax DevCenter is a visual CQL query tool for Cassandra and DataStax Enterprise.
How to start OpsCenter GUI: http://www.datastax.com/documentation/getting_started/doc/getting_started/gettingStartedInstallOpscTar_t.html
2. Package Installation:
DataStax All-in-One Installer
- You need to register with DataStax for DataStax All-in-One Installer download.
- DataStax Enterprise – http://www.datastax.com/download#dl-dseinstaller
- Installation : http://www.datastax.com/documentation/getting_started/doc/getting_started/gsInstallNonRoot.html
- Follow the installation steps given in above link and install.
- Once your Installation is completed, Your DataStax will be in following location:
- /Users//dse.
How to run DataStax?
- Cassandra:
- Go to your /Users//dse via Terminal and execute the following command:
- sudo ./bin/dse cassandra -f (This will start the cassandra)
- Opscenter and DataStax-Agent:
- Go to /Users//dse in new Tab and execute command :
- sudo ./opscenter/bin/opscenter -f (This will start the opscenter)
- Go to /Users//dse in new Tab and execute command :
- sudo ./datastax-agent/bin/datastax-agent -f (This will start the datastax-agent)
Using DataStax:
- Now you can see the Opscenter in Browser in following address:
- localhost:8888/
- Here You can able to see the your Cassandra cluster visually, (Kind of monitoring tool for cassandra)
- You need to start DevCenter which came with DataStax(You can find the shortcut for DevCenter in your Desktop), if you want to query and access the cassandra DB.
- Getting Started with DevCenter : http://www.datastax.com/what-we-offer/products-services/devcenter
Integrate Cassandra with Spring Data Cassandra :
-
/** * Created by: Rajiv Srivastava */ @Configuration @ComponentScan(basePackages = {com.cassandraproject.dao,com.cassandraproject.utils}) @EnableCassandraRepositories(basePackages ={com.cassandraproject.repository}) public class AuditCoreContextConfig extends AbstractCassandraConfiguration { @Override protected String getKeyspaceName() { return event_owner; //Schema or Keyspace name } @Override protected String getContactPoints() { return localhost;//IP address of server/local machine. Host of a clusters can be separated with comma (,) like host1,host2. Also minimum two host should be added, so that second Cassandra server will be connected if first is down. } @Override protected int getPort() { return 9042; //Cassandra DB port } }
2. Data Modelling
a. Primary/Clustered/Partioned key
/**
* Created by: Rajiv Srivastava
*/
/* Keyspac/Schema- event_owner
* CREATE TABLE event_owner.event_audit (
ctg text,
month timestamp,
ctgid text,
ver timeuuid,
userid text,
action text,
content text,
PRIMARY KEY ((ctg,month),ctgid,ver)
)WITH CLUSTERING ORDER BY (ctgid ASC, ver DESC);
*/
@PrimaryKeyClass
public class EventAuditKey implements Serializable {
private static final long serialVersionUID = 1L;
@PrimaryKeyColumn(name = ctg, ordinal = 0, type = PrimaryKeyType.PARTITIONED)
private String category;
@PrimaryKeyColumn(name = month, ordinal = 1, type = PrimaryKeyType.PARTITIONED)
private Date month;
@PrimaryKeyColumn(name = ctgid, ordinal = 2, type = PrimaryKeyType.CLUSTERED, ordering =Ordering.ASCENDING)
private String categoryId;
@PrimaryKeyColumn(name = ver, ordinal = 3, type = PrimaryKeyType.CLUSTERED, ordering = Ordering.DESCENDING)
private UUID version;
3. Repository
/**
* Created by: Rajiv Srivastava*/
@Repository
public interface AuditRepository extends CrudRepository <EventAudit, EventAuditKey> {
@Query(select * from event_owner.event_audit)
public List<EventAudit&> eventAudit();
}
4. CRUD Operation using JPA/CrudRepository – DAO Layer
/**
* Created by: Rajiv Srivastava*/
@Component
public class EventDaoImpl implements EventAuditDao {
@Autowired
public AuditRepository auditRepository;
@Override
public void save(EventAudit entity) {
auditRepository.save(entity);
}
@Override
public void save(Collection<EventAudit> entities) {
auditRepository.save(entities);
}
@Override
public EventAudit find(EventAuditKey eventAuditKey) {
if(null==eventAuditKey){
throw new IllegalArgumentException(It doesn't has all required instance variable set);
}
return auditRepository.findOne(eventAuditKey);
}
@Override
public List<EventAudit> getAll() {
Iterable<EventAudit> iterable=auditRepository.findAll();
if(null != iterable.iterator()){
return Lists.newArrayList(iterable.iterator());
}
return new ArrayList<>();
}
@Override
public List<EventAudit> getListEventAuditMonthCategoryWise(Date date, String Category) {
// TODO Auto-generated method stub
return null;
}
}
Apache Cassandra:
* Getting started: http://wiki.apache.org/cassandra/GettingStarted
* Join us in #cassandra on irc.freenode.net and ask questions
* Subscribe to the Users mailing list by sending a mail to
user-subscribe@cassandra.apache.org
* Planet Cassandra aggregates Cassandra articles and news:
For more on what commands are supported by CQL, see
https://github.com/apache/cassandra/blob/trunk/doc/cql3/CQL.textile. A
reasonable way to think of it is as, “SQL minus joins and subqueries.”
MongoDB + Java + Maven Sample Application
Prerequisite: Download and Install MongoDB (http://docs.mongodb.org/manual/installation/) on your local machine and run two instances in two separate terminal/command prompt. This sample app is developed on Mac OS/Linux env.
1. Start MongoDB server using : ./mongod
2. Start MongoDB client : ./mongo
Add MongoDB Jar dependency in your project:
<dependency> <groupId>org.mongodb</groupId> <artifactId>mongo-java-driver</artifactId> <version>2.10.1</version> </dependency>
Sample MONGODB CRUD code:
package com.db;
import java.util.List;
import java.util.Set;
import com.mongodb.BasicDBObject;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.DBCursor;
import com.mongodb.DBObject;
import com.mongodb.MongoClient;
public class MongoConnectionManager {
static DBCursor cursor;
public static void main(String[] args) {
try{
System.out.println("Connecting with MongoDB......");
//DB connection after ver 2.10.0
MongoClient mongoconn = new MongoClient("localhost",27017 );
//Get database
DB db = mongoconn.getDB( "test" );
System.out.println("Database Name: "+db.getName());
//Display all databases
List<String> dbs = mongoconn.getDatabaseNames();
for(String mydb : dbs){
System.out.println(mydb);
}
//If MongoDB is installed on Secure mode
//boolean auth = db.authenticate("username", "password".toCharArray());
//Get Collection/tables names
Set<String> colls = db.getCollectionNames();
for (String s : colls) {
System.out.println(s);
}
//Get Collection
DBCollection coll = db.getCollection("mynames");
coll.createIndex(new BasicDBObject("email", 1)); // create index on "i", ascending
System.out.printf("Collection Names:"+db.getCollectionNames());
//Drop collections
coll.drop();
//Insert new records/documents
BasicDBObject doc1 = new BasicDBObject();
//Insert values into document/record
doc1.put("name", "Rajiv");
doc1.put("email", "rajivmca2004@yahoo.com");
doc1.put("count",1);
// Insert values in Collection
coll.insert(doc1);
BasicDBObject doc2 = new BasicDBObject();
//Insert values into document/record
doc2.put("name", "Mohit");
doc2.put("email", "mohit@yahoo.com");
doc2.put("count",2);
// Insert values in Collection
coll.insert(doc2);
//Fecth only first doc
DBObject mydoc= coll.findOne();
System.out.println("Only First Doc :"+mydoc);
//Insert and fetch Multiple doc
for (int i = 0; i < 10; i++) {
coll.insert(new BasicDBObject().append("count", i));
}
//Total documents
cursor= coll.find();
while(cursor.hasNext()){
System.out.println(cursor.next());
}
//Getting A Single Document with A Query
BasicDBObject query= new BasicDBObject();
query.put("name","Rajiv");
cursor= coll.find(query);
System.out.print("Getting A Single Document with A Query: \n");
//Iterate over database results
while(cursor.hasNext()){
System.out.println(cursor.next());
}
//Conditional Queries, documents where i > 50. We could also get a range, say 20 < i <= 30 :
query = new BasicDBObject();
query.put("count", new BasicDBObject("$gt", 1).append("$lte", 30)); // i.e. 20 < i <= 30
cursor = coll.find(query);
while(cursor.hasNext()) {
System.out.println("Comparison =>"+cursor.next());
}
System.out.println("Total documents: "+coll.getCount());
} catch (Exception e) {
e.printStackTrace();
}
}
}
